The bitter lesson is true right now for clinical AI. And that’s ok.
General models are impressively capable. Clinical infrastructure determines whether they’re useful.
Introduction

A new Nature Medicine paper compared two specialized clinical AI tools, OpenEvidence and UpToDate Expert AI, with several frontier general-purpose models (Vishwanath et al. 2026). The headline result was hard to miss: the frontier models performed better across medical benchmarks and blinded clinician ratings of real clinical queries.
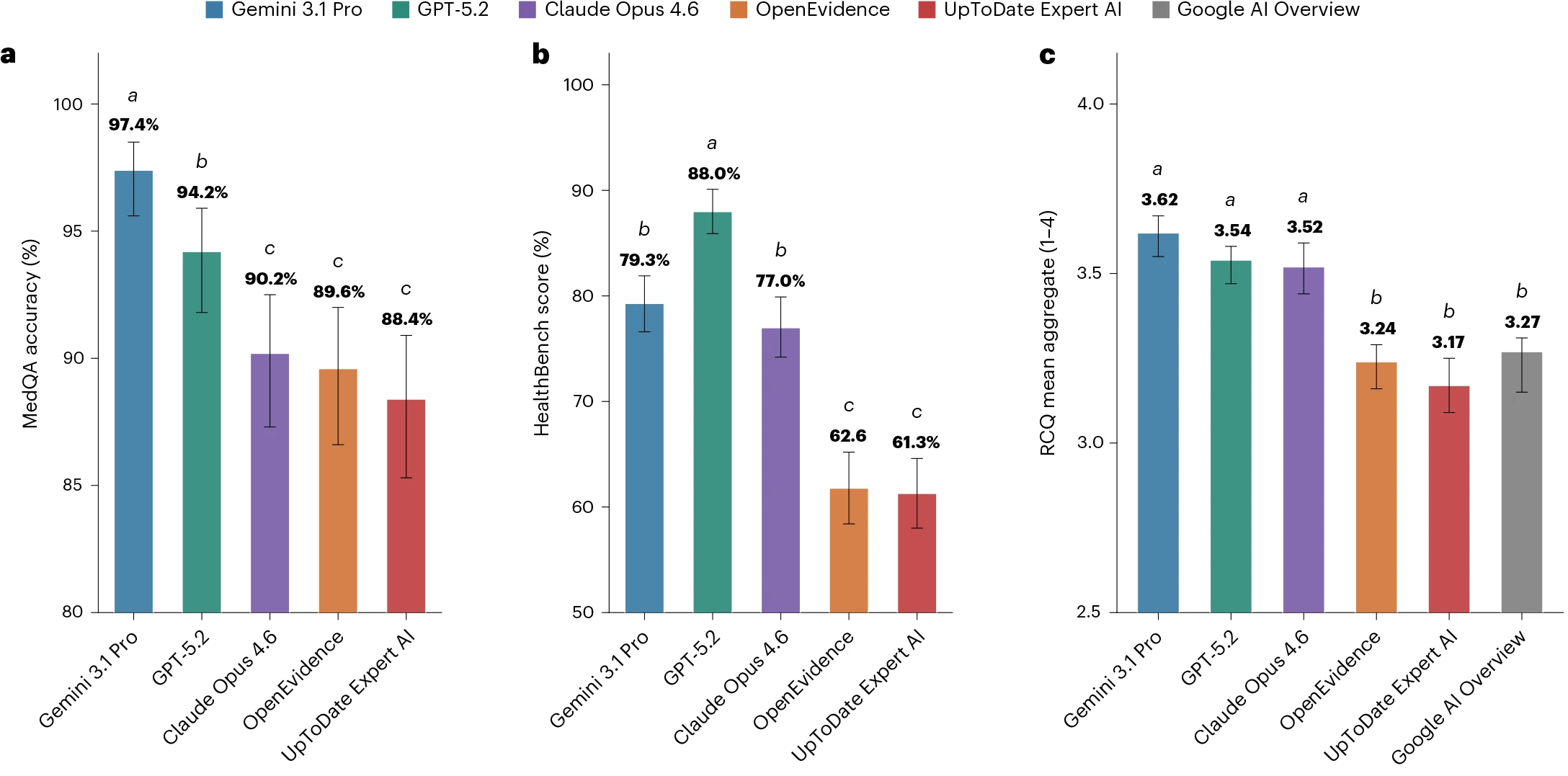
The results have been entertaining to watch. Eric Topol’s X post helped ignite the debate. OpenEvidence pushed back. Others pointed out real limitations in both directions: benchmark design is hard, proprietary systems are hard to evaluate, and clinical usefulness is not the same thing as a leaderboard score.
Now I do not think the paper settles the future of clinical AI. Scoring the quality of model output is hard, and this paper evaluates an extremely narrow slice of the many ways people might use a clinical AI system. So there are no definitive conclusions here.
Still, if we are careful not to overread it, the paper gives some support to a useful framing for people building clinical AI systems: the bitter lesson is true right now for medicine, and that is ok.
The bitter lesson is true right now
Richard Sutton’s bitter lesson is that general methods powered by computation tend to beat expert-crafted systems as scale increases (Sutton 2019). In clinical AI, that seems increasingly plausible. Frontier models did not become good at medical questions because they were engineered around a particular specialty workflow or knowledge base, like OpenEvidence or UTD AI. They became good because broad training, scale, tool use, and general reasoning improved.
That is the part worth taking seriously right now.
That is ok
The point is not despair. The point is where to build.
The value of clinical AI is only realized when the model interacts with the real, messy world of healthcare. This interaction requires well-designed infrastructure to ensure it is safe, effective, and beneficial.
A powerful general model is just one component of this system. Medicine needs expert-crafted machinery around the model, such as governance, audit trails, workflow integration, retrieval, citation standards, monitoring, escalation rules, input controls, output controls, and a sharply limited action surface. If the bitter lesson is true right now, that does not make clinical expertise less important. It makes the expert-built infrastructure around the model more important.
That should be encouraging for people building clinical AI infrastructure. The durable asset is not the model itself. Models will come and go. It may be OpenEvidence in one setting, Gemini in another, Claude in another, and an institutionally hosted model somewhere else. Headlines will crown a new AI champion every few months. The durable asset is the harness, the infrastructure that lets a model act safely in the real world. It is the clinical workflow that defines what the model can see, what it can do, how its claims are checked, when a human must intervene, and who is responsible for the result. A surgeon without an operating room is just a person who knows where to cut, and a frontier model without proper infrastructure is just a system that knows what to say.
So the practical lesson is not “frontier models win, specialized tools lose.” That is too simple. The lesson is to build as if the bitter lesson is true right now. Assume increasingly capable general models will keep arriving. Then build the clinical infrastructure that can use those models as safe references, swap them when better evidence appears, and keep the responsibility where it belongs.